
TL;DR
Native podcasts feel impossible because they push input past working memory’s 3–5 chunk limit. This creates a risk of information overload.
Speed (150–170 WPM), connected speech, idioms, and accents stack load simultaneously. Comprehension drops below 50%, and the brain disengages within 30 seconds.
This can be fixed by reducing load through slower playback, visual scaffolding, and anchor-based listening.
- Native speech runs 30–50% faster than learner audio.
- Working memory holds only 3–5 chunks of new information.
- Comprehension below 90% blocks language acquisition.
- Visual scaffolding lifts understanding by 20–40%.
Why does native content feel overwhelming?
Native content feels overwhelming because input is processed faster than working memory can handle. Speed, idioms, accents, and noise are stacked together.
The brain gets flooded in seconds. Meaning is lost before it can be built. Press play on a native podcast, and the brain is hit instantly.
Words blend together. Idioms are dropped without warning. The listener is pushed past the processing limit. This is not a motivation issue. It is a capacity issue.
What is information overload in language learning?
Information overload happens when input exceeds the brain’s processing capacity. It was defined by cognitive load theory, developed by John Sweller. The theory is built on three load types working together.
Intrinsic load is caused by the difficulty of the language itself. Extraneous load is caused by poor delivery, noise, or distractions. Germane load is the effort used to build real learning. Native podcasts max out all three at once.
| Load Type | What Causes It | Podcast Example |
| Intrinsic | Language complexity | Rare vocab, idioms |
| Extraneous | Poor delivery | Background noise, fillers |
| Germane | Learning effort | Building new schemas |
When the total load passes capacity, learning stops. The input is treated as noise.

How fast is native speech compared to learner audio?

Native podcasts are delivered at 150–170 words per minute. Learner audio is paced at 80–120 WPM. The gap is roughly 30–50%. That gap is felt as chaos by untrained ears. At 150+ WPM, less than 400 milliseconds are given per word.
Sounds must be decoded, matched to meaning, and linked to context in that window. For learners using controlled processing, the window is too short.
Words are missed before they are understood.
| Audio Type | WPM Range | Purpose |
| Native Podcast | 150–170 | Natural conversation |
| Slow Learner Audio | 80–120 | Comprehension training |
| Fast Native (edited) | 170+ | Documentaries, news |
Why does connected speech break comprehension?
Connected speech is when words blend into a continuous sound. Boundaries are erased by the speaker. “Put it on” is heard as /pʊdɪtɒn/. “Going to” becomes “gonna.”
Word boundaries must be rebuilt by the learner before meaning is accessed. Processing steps are doubled. Working memory is drained twice as fast. This is why familiar words are not recognized in native speech.
Common forms include:
- Catenation: consonant links to vowel (“an egg” → “anegg”)
- Elision: sounds are dropped (“next day” → “nexday”)
- Assimilation: sounds blend (“did you” → “dijou”)
- Reduction: weak forms replace full ones (“want to” → “wanna”)
Why does working memory fail so fast?
Working memory is limited. Modern research sets the ceiling at 3–5 chunks of new information, not the older 7±2 figure. That limit is dynamic. It shrinks when input is complex or unfamiliar.
Native speech exceeds this ceiling almost instantly. One phrase can carry multiple unknown sounds, idioms, and grammar patterns. Once the limit is passed, unprocessed information is lost within 10–20 seconds. Nothing is moved into long-term memory.
A double penalty is triggered by native audio. The ceiling is lowered, and the load is raised at the same time. This nonlinear effect is rarely explained in generic content.
What is the 30-second shutdown?
The “30-second shutdown” is not real silence. It is a shift in how the brain uses energy. When comprehension levels drop too low, attention is pulled away from the input.
Resources are conserved. Neural habituation kicks in. Auditory responses are reduced. Prefrontal effort is cut.
The listener is still hearing, but meaning is no longer extracted. This is why podcast content feels like a blur after half a minute.
What comprehension level is needed for learning?
Stephen Krashen’s input hypothesis sets the threshold at 90–95% comprehension. Below this level, context clues fail. Meaning cannot be inferred from what is known.
The input becomes noise. Most native podcasts push learners below 50%. At 30%, the brain gives up entirely. The affective filter is raised. Frustration is locked in.
| Comprehension Level | Brain Response | Learning Outcome |
| 90–95% | Low load, efficient uptake | Fast acquisition |
| 50–89% | Partial overload | Slow progress |
| Below 50% | Habituation, shutdown | No learning |
How much of native speech is slang and reductions?
Native conversations are packed with non-literal language.
Idioms, slang, and reduced forms are estimated at 15–25% of total speech. Reductions like “gonna,” “wanna,” and “gotta” appear every 1–2 minutes.
These forms do not match textbook language. Extra decoding is required. Meaning is not literal for idioms like “spill the beans” or “kick the bucket.” Each one eats into working memory.
Why do regional accents crash comprehension?
The brain relies on predictive processing. Future sounds are guessed based on past experience. When an accent breaks those predictions, errors are spiked.
Comprehension is cut in half during the first exposure. Partial adaptation is seen within 1–2 minutes. Comprehension is recovered by 20–30%. But adaptation only works if the total load stays manageable. In overloaded states, no adjustment is made.
A real example: the “Berlin Street Food” podcast!
Imagine a podcast about currywurst stalls in Berlin.
The host speaks at 160 WPM. Pots clang in the background. Words like “Wursthülle” and “Senfsoße” are dropped. Phones buzz nearby. Intrinsic load is maxed by the vocabulary.
Extraneous load is added by the noise and notifications. Germane load has no room left. Four working memory chunks are filled before the first sentence ends.
The shutdown starts within 30 seconds.
Why do native speakers sound so effortless?
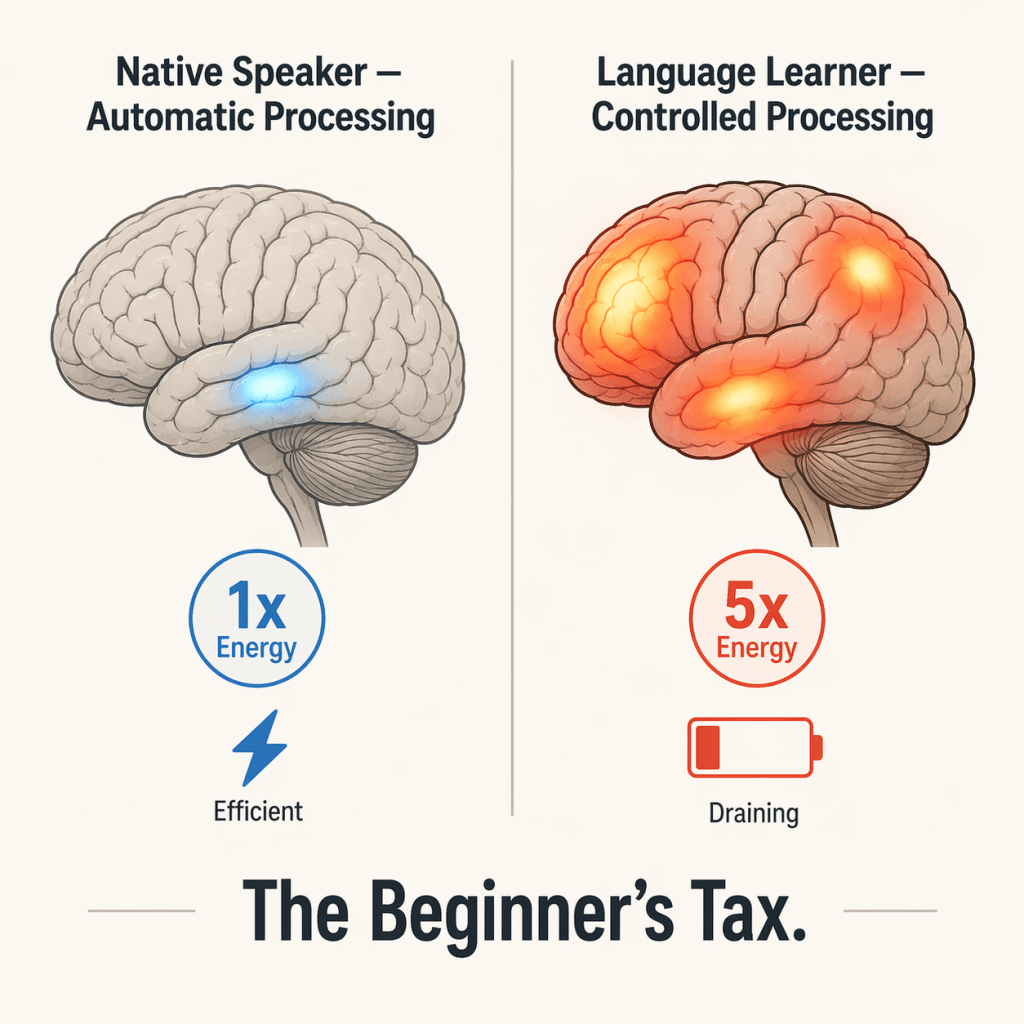
Automatic processing is used by native listeners. It is fast, parallel, and low-cost. Patterns are recognized without conscious effort. Energy use is minimal.
Controlled processing is used by learners. It is slow, sequential, and expensive. Up to 5x more energy is burned. The prefrontal cortex is drained. Fatigue is triggered within minutes.
| Mode | Energy Cost | Speed | Who Uses It |
| Automatic | 1x (low) | Fast, parallel | Natives |
| Controlled | 5x (high) | Slow, serial | Learners |
How can information overload be reduced?
Overload is managed by controlling three levers. Speed, support, and session length. When these are tuned, native input becomes workable. Without them, exposure stays painful.
- Slow the audio. 0.75x playback is shown to boost retention by 20–30%. Word boundaries are restored. Phonemes are heard clearly.
- Add visual scaffolding. Mouth movements and gestures raise comprehension by 20–40%. Netflix and YouTube work better than audio alone.
- Use dual subtitles. Target and native language are shown together. Extraneous load is cut. Retention is improved by 37% over single subtitles.
- Anchor to high-frequency words. The top 300 words cover 65% of speech. These act as cognitive islands. Comprehension is held together around them.
- Cap session length. Listening fatigue hits after 15–30 minutes. Performance drops 30–50% past that point. Short, focused blocks are favored.
Why don’t streak-based apps solve overload?
Gamified apps keep comprehension near 100%. Isolated vocabulary is drilled.
Load is kept artificially low. The brain is never trained for real chaos. Streaks reward button-tapping, not decoding under pressure.
App accuracy of 80–90% collapses to 30% in real podcasts. Anchor detection and prediction skills are never built. The plateau is structural, not personal.
How long does it take to reach comfortable comprehension?
Moving from CEFR A2 to B2 requires 300–450 hours of guided input. Total time from zero to B2 sits at 500–650 hours. Intensive practice cuts the timeline. Casual study extends it.
At 1 hour per day, 1–2 years is typical. At 3–5 hours per day, 6–12 months is possible. Language similarity and prior multilingual experience shave 20–30% off these numbers.
2026 and Future Predictions: Where Language Learning Is Headed
The shift from static flashcards to adaptive AI scaffolding is being driven by efficiency data.
Study time is projected to be cut by 30–50% when learning is embedded in real content. Flashcards are being replaced by context-aware systems.
- AI-mediated immersion adoption is forecast to reach 60–75% of learners by 2027, up from 15–25% in 2024. Entertainment and study are being blurred into one activity. Netflix scenes are being converted into shadowing drills and grammar lessons automatically.
- Over-scaffolding is being flagged as a new risk. When AI removes too much load, germane learning is skipped. Mental fatigue shows up later in the process. Some effort must be kept in the learning loop.
- Working memory is now measured indirectly. Most 2026 AI tools track proxy metrics like error rate and response latency. Actual brain capacity is not being improved. Perceived load is being reduced through better design.
- Attention spans are being rebuilt intentionally. Short-form content has dropped focus windows to 8–15 seconds. Podcast-length input feels harder than it did a decade ago. Tools are being designed to gradually extend sustained attention.
| Era | AI Immersion % | Overload Risk | Learning Style |
| 2024 | 15–25% | High (raw streams) | Micro + Play |
| 2027 | 60–75% | Low (curated) | Blended Deep Work |
FAQs
Why do native speakers sound so fast?
Connected speech and reductions blend words together. Natural pace is 150–170 WPM, nearly double learner audio speed.
Is it normal to not understand podcasts?
Yes. Working memory caps comprehension below the 90% threshold required for learning. This is structural, not a skill gap.
Should native content be avoided?
No. But it should be paired with scaffolding tools. Raw native input without support reinforces overload.
How long before native podcasts feel easy?
Comfort is typically reached between B2 and C1, around 500–700 hours of guided input. Contextual tools shorten this window.
Does slowing audio damage pronunciation?
No. Short-term elongation is normalized by the brain through exposure. Alternating between 0.75x and 1x builds accurate timing.
What’s better for overload: podcasts or video?
Video. Visual scaffolding adds 20–40% comprehension. Audio-only is harder because phoneme cues from lips and gestures are missing.
Final Word
Native content is unmanaged rather than impossible. High processing loads cause comprehension to collapse quickly. The fix is structural.
You must slow the speed and add visual anchors. Keep input near the 90% threshold to stay in control. Fluency comes from offloading smarter.
Treat tools as cognitive partners instead of crutches. Beat the final boss by lowering the load rather than raising the effort.
How Jolii Helps You Beat Information Overload?
Jolii is built on contextual immersion. YouTube and Netflix content is turned into interactive lessons. Clickable words, dual subtitles, and scene-based quizzes are layered on top.
Input is kept inside the 90–95% comprehension zone through AI scaffolding. The “i+1” level is maintained automatically, so overload is prevented without removing real content.
Try Jolii on a show you already watch. The boss-level podcast becomes a winnable level.




